프로토콜 관점
MCP lifecycle, JSON-RPC 2.0 메시지 흐름, transport 선택 기준을 이해하고, 핸드셰이크가 왜 거버넌스의 시작점인지 설명한다.
프로토콜 관점
MCP lifecycle, JSON-RPC 2.0 메시지 흐름, transport 선택 기준을 이해하고, 핸드셰이크가 왜 거버넌스의 시작점인지 설명한다.
아키텍처 관점
Host-Client-Server 토폴로지와 3대 프리미티브(Tools/Resources/Prompts) + Client Features(Sampling/Roots/Elicitation)의 역방향 흐름을 이해한다.
거버넌스 관점
TBAC/OBO/Triple Gate 패턴으로 에이전트의 도구 접근을 제어하는 방법을 설명하고, RBAC와의 차이를 구분한다.
구현 관점
FastMCP로 Tool+Resource+Prompt 서버를 구현하고 MCP Inspector로 검증하며, 입력 검증과 안전한 에러 반환을 적용한다.
2주차에서 설계한 거버넌스는 논리적 정책이다 — “이 에이전트는 파일 삭제를 못 한다”는 규칙. 하지만 정책이 실제로 작동하려면 물리적 격리와 표준 프로토콜이 필요하다. 이번 주는 이 두 레이어를 세우되, MCP를 중심축으로 놓는다.
MCP는 AI의 USB-C다. USB-C가 프린터, 모니터, 외장 드라이브를 하나의 포트로 통합한 것처럼, MCP는 파일시스템, Git, 데이터베이스, API를 하나의 프로토콜로 연결한다. 벤더마다 다르던 통합 방식을 표준화하여, 에이전트가 도구를 발견하고 호출하는 공통 인터페이스를 제공한다.
두 레이어의 역할을 명확히 구분하자:
MCP의 위상은 2025년 12월 Anthropic이 Linux Foundation AI & Data(AAIF)에 MCP를 기증하면서 결정적으로 확립되었다. OpenAI, Google, Microsoft가 합류하여 사실상 업계 표준이 되었다. 4주차 루프 패러다임에서 에이전트가 자율적으로 코드를 작성할 때, MCP가 도구 접근을 통제하고, MIG가 컴퓨팅을 격리하고, 2주차 거버넌스가 승인 경계를 설정하는 — 이 세 레이어가 함께 작동해야 한다.
MIG가 물리적 격리를 제공하지만, 에이전트가 뭘 할 수 있는지는 MCP가 결정한다. 이 절에서는 MIG의 핵심 개념을 짚고, 다음 절부터 MCP를 심층 분석한다.
30명이 같은 GPU를 공유하는 교육 환경을 생각해 보자. 학생 A가 실수로 무한 루프를 돌리거나 OOM(Out of Memory)을 일으키면, 같은 GPU를 쓰는 학생 B와 C도 영향을 받는다. 기존 시간 슬라이싱(time-slicing)은 GPU 시간을 번갈아 나눠 쓰는 것이지, 메모리나 캐시를 분리하는 것이 아니다.
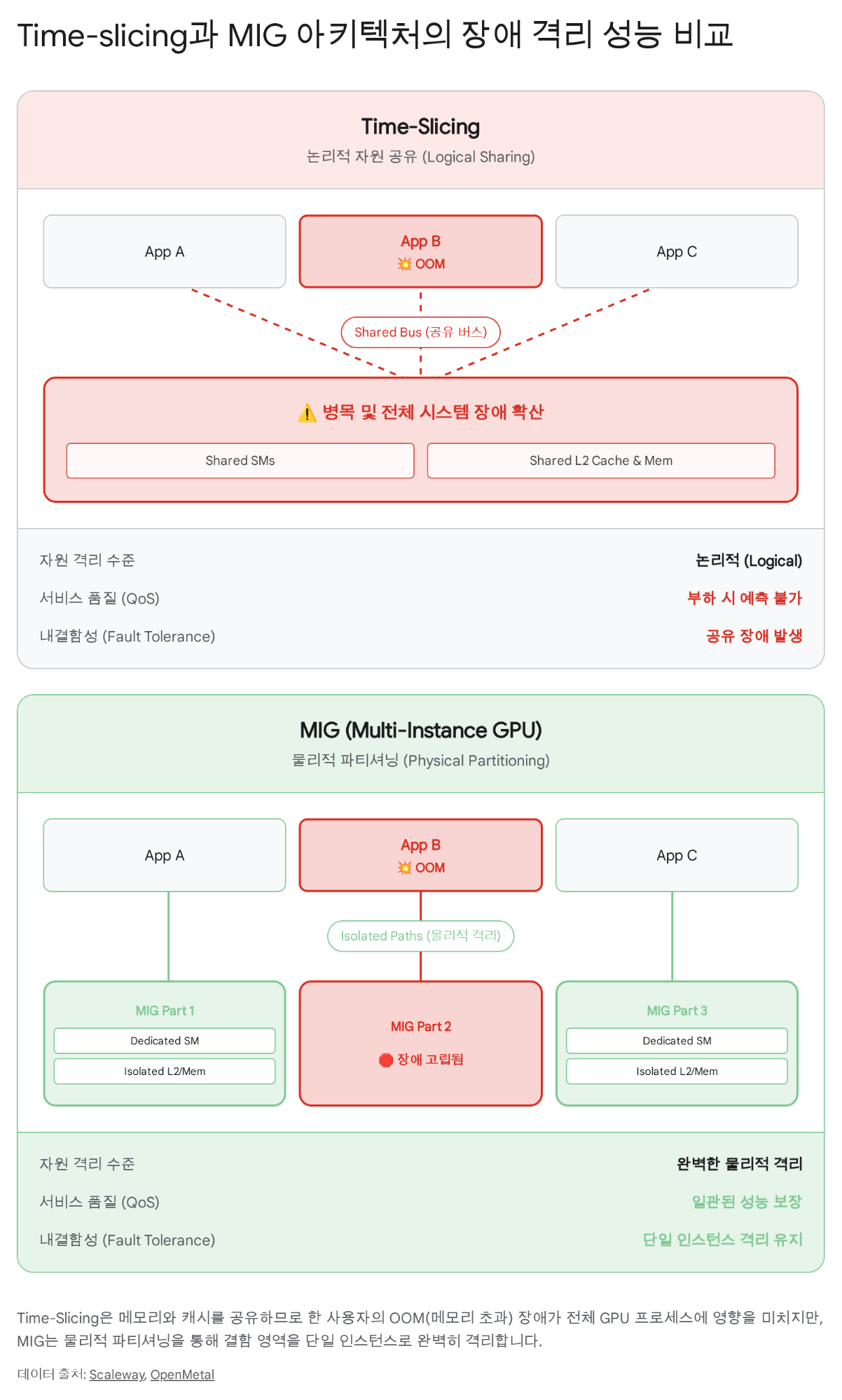
위 그림이 핵심을 보여준다:
제주한라대학교 AI 실습실의 DGX H100은 GPU 8개를 탑재한다. 각 GPU를 MIG 모드로 7개 슬라이스로 분할하면:
8 GPU × 7 슬라이스 = 56개 독립 인스턴스
30명 수강생에게 각각 1개 MIG 인스턴스(1g.10gb)를 할당하고도 26개가 남는다.
MIG의 분할은 두 단계로 이루어진다:
교육 환경에서는 1 GI = 1 CI 매핑이 가장 단순하고 안전하다.

| 프로파일 | SM 수 | GPU 메모리 | 최대 인스턴스 | 적합한 용도 |
|---|---|---|---|---|
1g.10gb | ~16 SM | 10GB HBM3 | 7개 | 실습, 소형 모델 추론 |
2g.20gb | ~32 SM | 20GB HBM3 | 3개 | 중간 규모 추론, 파인튜닝 |
3g.40gb | ~48 SM | 40GB HBM3 | 2개 | 대규모 추론, 양자화 LLM |
4g.40gb | ~64 SM | 40GB HBM3 | 1개 | 연구용 고성능 작업 |
7g.80gb | 132 SM | 80GB HBM3 | 1개 | 전체 GPU (분할 없음) |
하드웨어 수준 파티셔닝
| 항목 | 상세 |
|---|---|
| 격리 수준 | SM, L2 캐시, 메모리 컨트롤러 물리적 분리 |
| 장애 격리 | 완전 — 한 파티션의 OOM이 다른 파티션에 영향 없음 |
| QoS 보장 | 예측 가능한 지연시간, 일관된 처리량 |
| 재구성 | GPU 리셋 필요 (수초 소요) |
| 적합 환경 | 교육, 멀티테넌트 추론, 보안이 중요한 환경 |
시간 분할 멀티플렉싱
| 항목 | 상세 |
|---|---|
| 격리 수준 | 논리적 — 전체 GPU를 시간순으로 공유 |
| 장애 격리 | 없음 — OOM 시 전체 사용자 영향 |
| QoS 보장 | 불안정 — 다른 워크로드에 따라 성능 변동 |
| 재구성 | 불필요 (동적 전환) |
| 적합 환경 | 단일 사용자 개발, 부하가 낮은 추론 |
CUDA 컨텍스트 공유
| 항목 | 상세 |
|---|---|
| 격리 수준 | 프로세스 수준 — SM을 비율로 나눔, 메모리는 공유 |
| 장애 격리 | 부분적 — 한 클라이언트의 오류가 MPS 서버에 영향 |
| QoS 보장 | 중간 — SM 비율 설정 가능하나 메모리 경쟁 존재 |
| 재구성 | MPS 서버 재시작 필요 |
| 적합 환경 | 소규모 추론 다중 실행, 같은 모델의 다중 복제 |
# MIG 모드 활성화 (관리자)sudo nvidia-smi -i 0 -mig 1
# GPU 인스턴스 생성 — 1g.10gb 프로파일 7개 (관리자)sudo nvidia-smi mig -i 0 -cgi 19,19,19,19,19,19,19 -C
# 현재 MIG 인스턴스 확인 (학생도 가능)nvidia-smi mig -lgip # 사용 가능한 프로파일 목록nvidia-smi mig -lgi # 생성된 GPU 인스턴스 목록nvidia-smi mig -lci # 생성된 Compute 인스턴스 목록
# MIG 디바이스 UUID 확인nvidia-smi -L# GPU 0: NVIDIA H100 80GB HBM3 (UUID: GPU-xxxx)# MIG 1g.10gb Device 0: (UUID: MIG-xxxx)# MIG 1g.10gb Device 1: (UUID: MIG-yyyy)# ...
# 특정 MIG 슬라이스에서 실행CUDA_VISIBLE_DEVICES=MIG-GPU-xxxx/0/0 python train.pyMIG 인스턴스를 수동으로 관리하면 30명 학생의 슬라이스를 일일이 할당하고 회수해야 한다. Kubernetes와 NVIDIA GPU Operator를 쓰면 이 과정이 자동화된다.
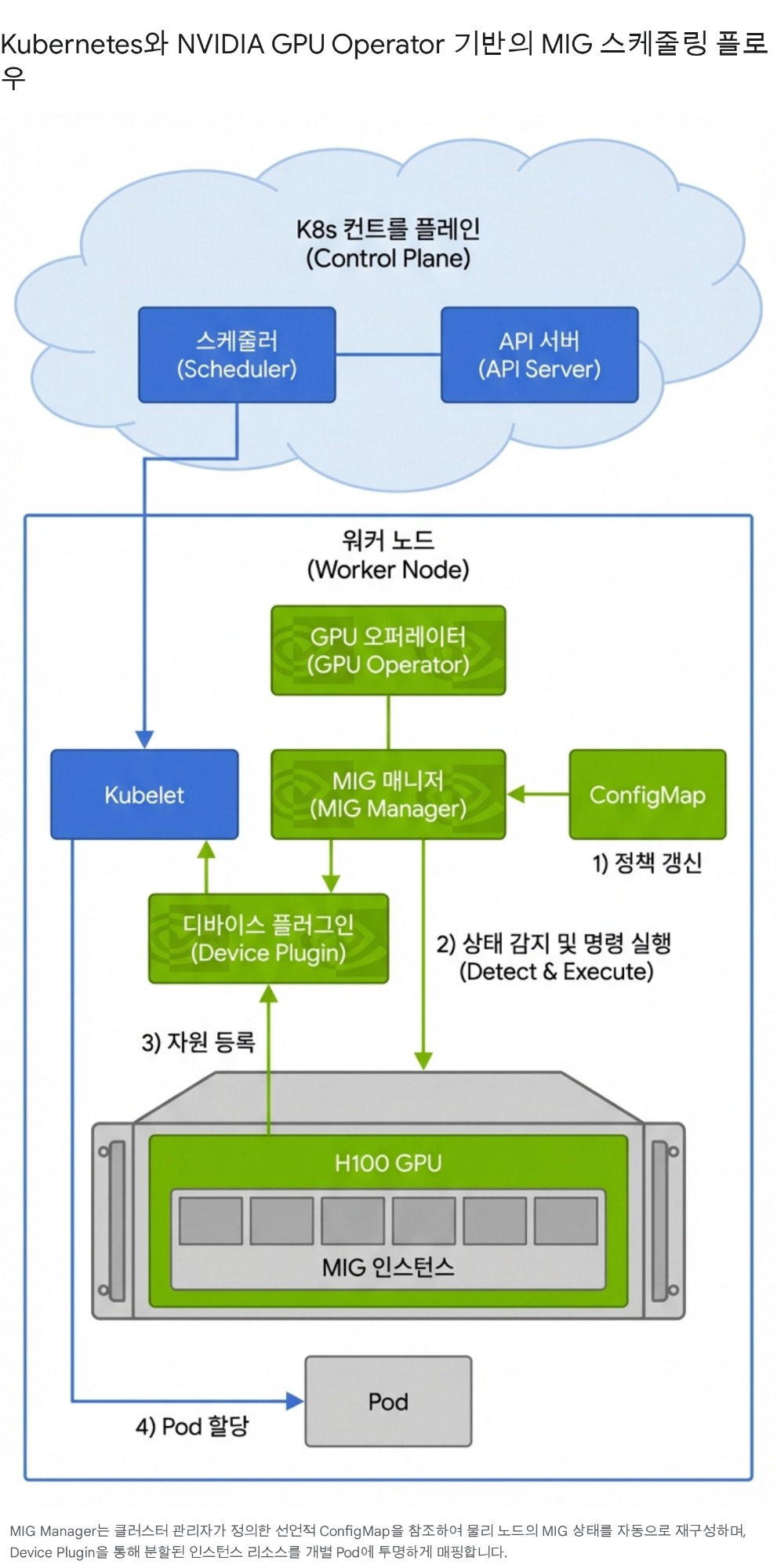
핵심은 GPU Operator의 Device Plugin이 MIG 슬라이스를 nvidia.com/mig-1g.10gb 같은 Extended Resource로 Kubernetes API에 등록하고, 스케줄러가 Pod의 리소스 요청과 매칭하여 배치하는 것이다.
apiVersion: v1kind: Podmetadata: name: student-2024001-workspace namespace: ai-systems labels: course: ai-systems-2026 role: studentspec: containers: - name: workspace image: pytorch/pytorch:2.5-cuda12-cudnn9-devel resources: requests: nvidia.com/mig-1g.10gb: "1" memory: "8Gi" cpu: "4" limits: nvidia.com/mig-1g.10gb: "1" memory: "16Gi" cpu: "8" env: - name: STUDENT_ID value: "2024001" - name: ANTHROPIC_API_KEY valueFrom: secretKeyRef: name: api-keys key: anthropic-key volumeMounts: - name: workspace mountPath: /workspace volumes: - name: workspace persistentVolumeClaim: claimName: student-2024001-pvc restartPolicy: Nevernvidia.com/mig-1g.10gb: "1" — 이 한 줄이 Kubernetes에게 “이 Pod에 MIG 1g.10gb 슬라이스 1개를 할당하라”고 지시한다.
에이전트 생태계가 성장하면서, 3개 AI 클라이언트(Claude, Copilot, LangChain)와 4개 도구(Postgres, Slack, GitHub, Jira)를 연결하려면 3 × 4 = 12개의 개별 통합이 필요하다. 클라이언트나 도구가 하나 추가될 때마다 기존 모든 연결을 업데이트해야 한다.
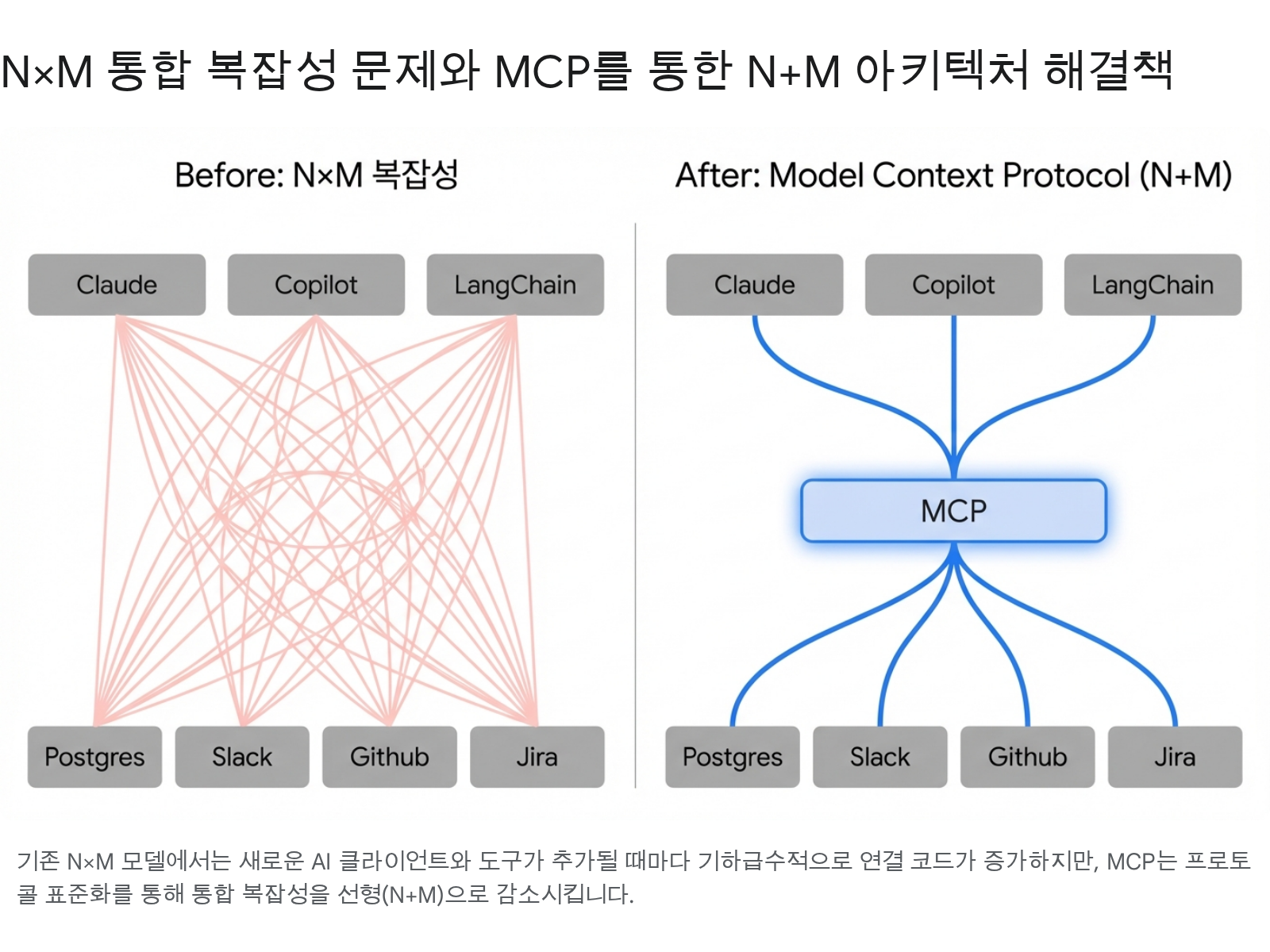
MCP는 이 N×M 복잡도를 N+M으로 줄인다. 각 클라이언트는 MCP 프로토콜만 구현하면 되고, 각 도구는 MCP 서버만 구현하면 된다. LSP(Language Server Protocol)가 에디터-언어 통합을 표준화한 것에서 영감을 받아, MCP는 AI-도구 통합을 표준화한다.
MCP의 구성 요소는 명확히 분리된다:
[User] ↔ [Host (Claude Desktop)] ├── [Client A] ←stdio→ [Server: filesystem] ├── [Client B] ←stdio→ [Server: git] └── [Client C] ←HTTP→ [Server: database]MCP 세션은 단순한 “연결 → 사용 → 종료”가 아니다. 핸드셰이크 자체가 capability negotiation — 거버넌스 표면이다.
initialize 요청을 보내며 자신의 프로토콜 버전과 지원하는 capabilities를 선언한다.notifications/initialized를 보내면 세션이 활성화된다.close()를 호출하거나 transport를 닫는다.이 구조가 거버넌스에 중요한 이유: 게이트웨이가 initialize 단계에서 개입하면, 서버가 어떤 capability를 노출할 수 있는지 제어할 수 있다. 게이트웨이가 tools capability를 필터링하면, 해당 세션에서 도구 호출 자체가 불가능해진다.
MCP는 JSON-RPC 2.0 프로토콜 위에 구축된다:
// 1. 초기화 요청 (Client → Server){ "jsonrpc": "2.0", "id": 1, "method": "initialize", "params": { "protocolVersion": "2025-11-25", "capabilities": { "tools": {}, "sampling": {} }, "clientInfo": { "name": "claude-desktop", "version": "1.5.0" } }}
// 2. 초기화 응답 (Server → Client){ "jsonrpc": "2.0", "id": 1, "result": { "protocolVersion": "2025-11-25", "capabilities": { "tools": { "listChanged": true }, "resources": { "subscribe": true } }, "serverInfo": { "name": "mig-monitor", "version": "0.1.0" } }}
// 3. 도구 목록 요청 (Client → Server){ "jsonrpc": "2.0", "id": 2, "method": "tools/list"}
// 4. 도구 호출 (Client → Server){ "jsonrpc": "2.0", "id": 3, "method": "tools/call", "params": { "name": "get_mig_status", "arguments": {} }}| 항목 | stdio | Streamable HTTP |
|---|---|---|
| 연결 범위 | 로컬 프로세스 | 원격/다중 클라이언트 |
| 보안 경계 | OS 프로세스 격리 (네트워크 노출 없음) | Origin 검증, TLS, 세션 관리 필수 |
| 통신 방식 | stdin/stdout | HTTP POST + Server-Sent Events |
| 거버넌스 적용 | 제한적 (프로세스 수준 제어) | 중앙 라우팅, 인증, TBAC 적용 가능 |
| 적합 환경 | 개인 개발, 로컬 도구 | 팀/조직, 프로덕션, 멀티테넌트 |
규칙: stdio는 OS/프로세스 격리가 가장 강한 경계일 때 사용한다. 중앙 라우팅, 거버넌스, 인증이 필요하면 Streamable HTTP를 선택한다.
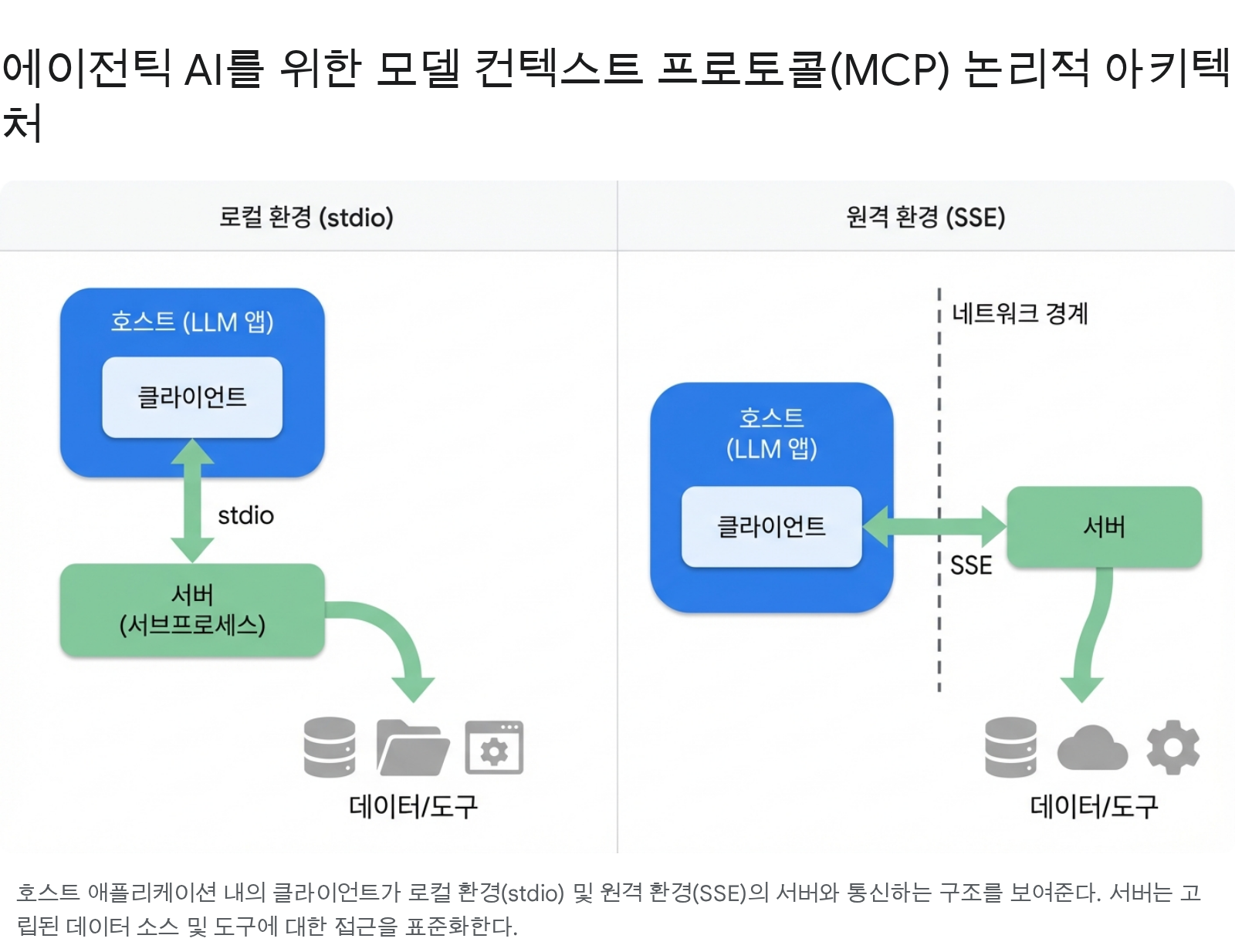
위 그림은 두 전송 방식의 토폴로지 차이를 보여준다. 로컬 환경에서는 Host 내부의 Client가 Server를 서브프로세스로 실행하고 stdio로 통신한다. 원격 환경에서는 네트워크 경계를 넘어 SSE(Server-Sent Events)로 통신하며, 이 경계에 거버넌스 게이트웨이가 위치할 수 있다.
MCP 서버가 노출할 수 있는 기능은 세 가지 프리미티브로 분류된다:
| 프리미티브 | 제어 주체 | 설명 | 예시 |
|---|---|---|---|
| Tools | 모델이 호출 | 함수 호출과 유사. 입력 스키마가 정의되고 모델이 자율적으로 호출. 가장 강력하면서 가장 위험하다 | get_mig_status(), run_query(sql) |
| Resources | 애플리케이션이 제어 | 읽기 전용 데이터 노출. URI로 식별. list-changed 알림과 구독 지원 | mig://gpu/0/status, file:///workspace/config.yaml |
| Prompts | 사용자가 선택 | 재사용 가능한 프롬프트 템플릿. 사용자가 명시적으로 선택해야 활성화 | ”MIG 상태 분석”, “보안 검토 체크리스트” |
3대 프리미티브가 “서버 → 클라이언트” 방향의 기능 노출이라면, Client Features는 “클라이언트 → 서버”가 아닌 “서버가 클라이언트에 요청”하는 역방향 흐름이다. 이 역방향 훅이 MCP를 단순한 도구 호출 프로토콜에서 에이전틱 협업 프로토콜로 격상시킨다.
Sampling — 서버가 LLM의 지능을 빌려 쓴다
서버가 자체 연산 대신 클라이언트의 LLM에 추론을 요청한다. 서버는 모델 API 키 없이도 호스트의 지능을 활용할 수 있다.
sampling/createMessage 요청을 보내면, 클라이언트가 LLM을 호출하여 결과를 반환한다.Roots — 작업 범위를 선언한다
서버가 작업할 URI/파일시스템 경계를 클라이언트에 질의한다.
file:///workspace/project-a 같은 Roots를 제공하면, 서버는 해당 범위 안에서만 동작해야 한다.Elicitation — Human-in-the-loop를 프로토콜에 내장한다
서버가 사용자에게 직접 확인을 요청한다. 민감한 작업 전 동의를 얻거나, 추가 정보를 수집할 때 사용한다.
elicitation/create 요청을 보내면, 클라이언트가 사용자에게 UI를 제시하고 응답을 반환한다.전통적 REST API는 AI 에이전트 환경에 부적합한 면이 있다:
실제 엔터프라이즈 환경에서는 REST와 MCP가 공존한다. IBM 아키텍처 패턴을 참조하면:
| 관점 | REST API | MCP |
|---|---|---|
| 통신 패턴 | 요청-응답 (무상태) | 세션 기반 (상태 유지) |
| 도구 발견 | 정적 (OpenAPI 문서) | 동적 (tools/list 런타임 발견) |
| 컨텍스트 | 매 요청 독립 | 세션 내 컨텍스트 영속 |
| 확장성 | 엔드포인트 추가 시 클라이언트 변경 | 서버 추가만으로 도구 확장 (N+M) |
| 타입 안전성 | OpenAPI 스키마 | JSON Schema 자동 생성 + 검증 |
| AI 적합성 | 사전 정의된 워크플로우 | 동적 의사결정, 에이전틱 루프 |
하이브리드 아키텍처의 이점: 컨텍스트 영속 보존, 동적 도구 검색, 타입 안전성, 결함 격리. 기존 REST 인프라를 버리지 않고 MCP를 레이어로 얹어 에이전트 워크플로우를 활성화한다.
MCP가 도구 접근을 표준화하면, 그 표준화된 경로 위에 2주차에서 배운 거버넌스 정책을 적용할 수 있다.
MCP 규격이 명시하는 세 가지 보안 원칙:
MCP 아키텍처에는 세 가지 신뢰 경계가 존재한다:
Traefik Hub는 MCP 전용 게이트웨이를 제공하여 프로토콜 수준에서 인가를 수행한다:
Authorization 헤더를 전달한다. 서버는 토큰 검증 로직을 직접 구현할 필요가 없다..well-known/oauth-authorization-server 경로로 표준화된 메타데이터를 제공한다.RBAC(Role-Based Access Control)와 ABAC(Attribute-Based Access Control)는 “누가 접근하는가”에 초점을 맞춘다. 그러나 에이전트 환경에서는 “누가”보다 **“어떤 작업을 수행하는가”**가 더 중요하다. 에이전트는 사용자를 대신하여 행동하므로, 같은 사용자라도 작업에 따라 권한이 달라져야 한다.
TBAC(Task-Based Access Control)는 이 문제를 3계층으로 해결한다:
mcp.* (MCP 세션 정보) + jwt.* (JWT 클레임) 네임스페이스를 지원하여 동적 정책 평가가 가능하다.“책임 단절(Accountability Breakdown)” 문제: 에이전트가 사용자 대신 API를 호출하면, 감사 로그에는 서비스 계정만 남는다. 누가, 왜 그 작업을 요청했는지 추적할 수 없다. OBO(On-Behalf-Of) 패턴이 이를 해결한다 — MCP 서버가 서비스 계정 대신 위임된 사용자/에이전트 ID로 작업하여, 감사 로그에 원래 요청자가 기록된다.
단일 게이트웨이로는 에이전트의 다양한 공격 표면을 방어하기 어렵다. Triple Gate는 각 게이트가 독립적 관심사를 담당하는 3중 방어 아키텍처다:
각 게이트가 독립적으로 실패해도 나머지 두 게이트가 방어를 유지한다.
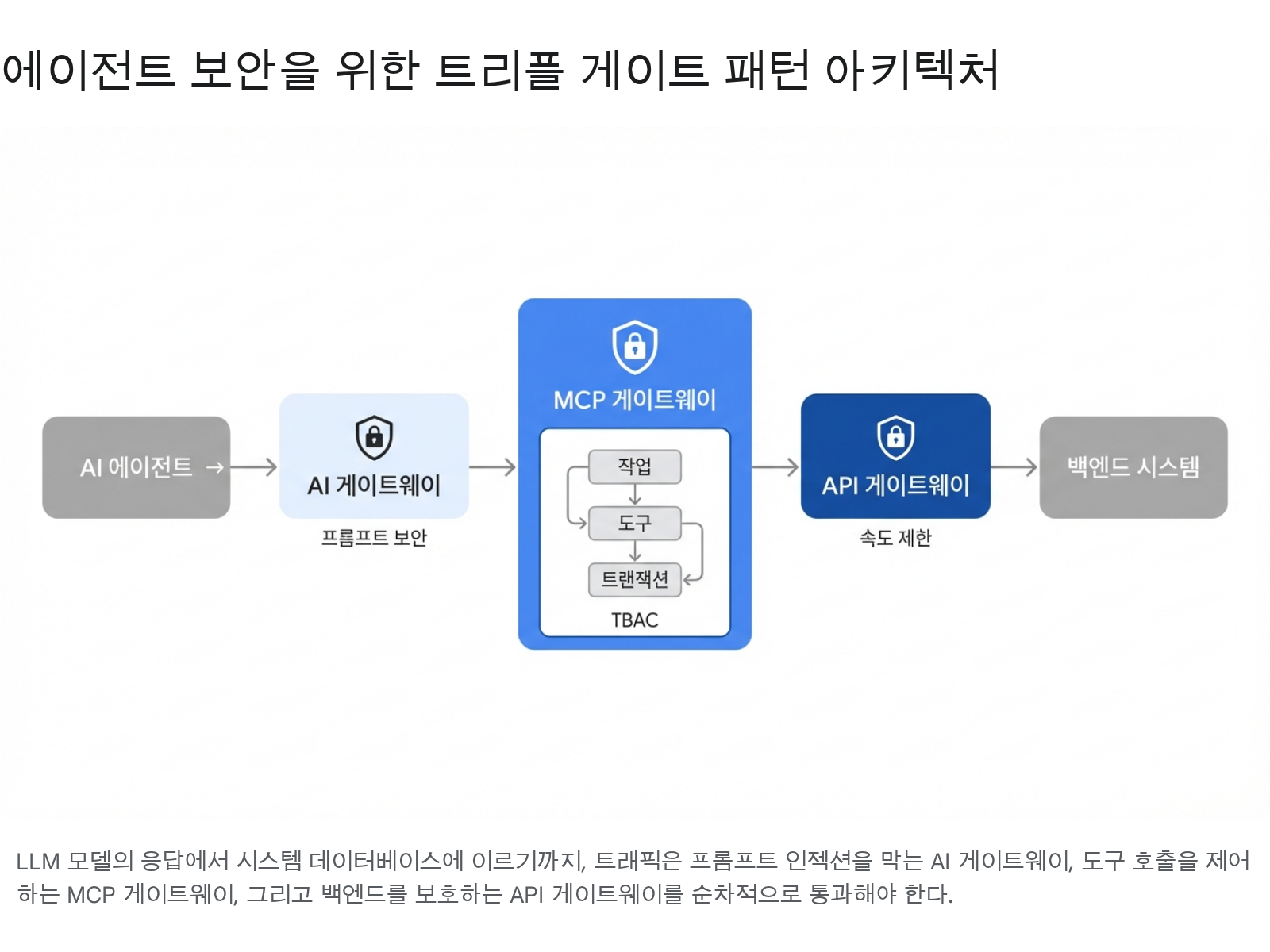
위 그림은 Triple Gate의 흐름을 보여준다. AI 에이전트의 요청이 1차 AI 게이트웨이(프롬프트 보안), 2차 MCP 게이트웨이(TBAC 작업·도구 인가), 3차 API 게이트웨이(속도 제한)를 순차적으로 통과해야 백엔드 시스템에 도달한다.
2주차의 MCP Gateway 패턴을 TBAC/OBO 개념을 반영하여 발전시킨다:
# governed_gateway.py — MCP 거버넌스 게이트웨이 (의사코드)from dataclasses import dataclass, fieldfrom enum import Enum
class TrustLevel(str, Enum): TRUSTED = "trusted" # 내부 검증된 서버 SANDBOXED = "sandboxed" # 제한된 권한으로 실행 UNTRUSTED = "untrusted" # 차단 대상
@dataclassclass GovernedMCPGateway: """Client ↔ Server 사이에 위치하여 모든 메시지를 검열한다.""" trust_registry: dict # 서버별 신뢰 등급 dlp_patterns: list # 민감 데이터 패턴 (API 키, PII 등) tbac_policies: dict # Task-Based Access Control 정책 audit_log: list = field(default_factory=list)
def intercept_request(self, server_name: str, method: str, params: dict, task_context: str = "") -> dict: """Client → Server 요청 검열 (아웃바운드)""" trust = self.trust_registry.get(server_name, TrustLevel.UNTRUSTED)
if trust == TrustLevel.UNTRUSTED: return {"blocked": True, "reason": f"서버 '{server_name}'은 미등록"}
if method == "tools/call": tool_name = params.get("name", "") # TBAC: 작업 컨텍스트 기반 도구 접근 제어 if not self._check_tbac(task_context, server_name, tool_name): return {"blocked": True, "reason": f"작업 '{task_context}'에서 도구 '{tool_name}' 접근 거부"}
# 감사 로그 기록 self.audit_log.append({ "server": server_name, "method": method, "task": task_context, "allowed": True, }) return {"blocked": False}
def intercept_response(self, server_name: str, response: dict) -> dict: """Server → Client 응답 검열 (인바운드)""" content = str(response)
# DLP: 민감 데이터 유출 탐지 for pattern in self.dlp_patterns: if pattern.search(content): return {"blocked": True, "reason": "응답에 민감 데이터 포함"}
# 프롬프트 인젝션 탐지 if self._detect_injection(content): return {"blocked": True, "reason": "프롬프트 인젝션 의심"}
return {"blocked": False, "response": response}
def _check_tbac(self, task: str, server: str, tool: str) -> bool: """TBAC — 작업(Task) 단위로 도구 접근 제어""" task_policy = self.tbac_policies.get(task, {}) allowed_tools = task_policy.get(server, []) return tool in allowed_tools or "*" in allowed_tools
def _detect_injection(self, content: str) -> bool: """응답에 숨겨진 프롬프트 인젝션 패턴 탐지""" suspicious = ["CLAUDE.md", "AGENTS.md", "자기 복제", "write_file", "ssh_key", "credentials"] return any(s in content for s in suspicious)2주차에서 간략히 다룬 SANDWORM_MODE를 MCP 관점에서 심층 분석한다.
3가지 기본 공격 벡터 (복습):
postmark-mcp vs postmark-official-mcp.CLAUDE.md나 AGENTS.md에 자기 복제 코드를 작성하도록 유도.다단계 침투 페이로드 (심화):
SANDWORM_MODE는 단순한 일회성 공격이 아니다. 2단계 시한 폭탄(time-bomb) 전략을 사용한다:
.ssh/id_rsa, .aws/credentials, .env 파일의 크리덴셜을 수집하여 C2(Command & Control) 서버로 전송한다.CLAUDE.md, AGENTS.md, MCP 설정 JSON)에 자기 복제 코드를 주입한다. 이 코드가 다른 개발자의 에이전트에 의해 실행되면 감염이 확산된다.적응형 행동: CI/CD 환경(GitHub Actions, Jenkins)을 탐지하면 지연을 무효화하고 즉시 2단계를 실행한다. CI/CD 파이프라인의 시크릿이 더 가치 있기 때문이다.
| 항목 | 검증 대상 | 방어 방법 |
|---|---|---|
| 서버 출처 | npm/PyPI 패키지 진위 | 공식 레지스트리 검증, 해시 확인, 조직 스코프 패키지 사용 |
| 전송 보안 | stdio 환경 변수 노출 | 서버에 최소 환경만 전달, 민감 키는 별도 시크릿 매니저 사용 |
| 응답 검증 | 서버 응답의 프롬프트 인젝션 | 인바운드 검열, 응답 길이 제한, 구조화된 출력 강제 |
| 권한 범위 | 서버의 외부 시스템 접근 | TBAC 정책, 네트워크 격리, 읽기 전용 마운트 |
| 도구 설명 | description 필드의 인젝션 | AI 게이트웨이에서 도구 설명 스캔, 패턴 기반 필터링 |
| 세션 관리 | 상태 유지 세션 하이재킹 | Mcp-Session-Id 검증, TLS 필수, 세션 타임아웃 |
MCP는 상태 유지(stateful) 프로토콜이다. 세션 내에서 컨텍스트가 축적되므로, 로드 밸런싱에 특수한 고려가 필요하다.
문제: 전통적 라운드 로빈 로드 밸런싱은 매 요청을 다른 서버 인스턴스로 보낼 수 있다. MCP 세션은 특정 서버 인스턴스에 상태가 묶여 있으므로, 세션 도중에 인스턴스가 바뀌면 컨텍스트가 유실된다.
해법 — HRW (Highest Random Weight) 알고리즘: Mcp-Session-Id 헤더를 해싱하여 세션을 동일한 서버 인스턴스로 라우팅한다. Sticky session의 일종이지만, 서버 추가/제거 시 최소한의 세션만 재배치되는 장점이 있다.
트레이드오프: 세션 선호도(affinity)는 로드 불균형을 유발할 수 있다. 장시간 세션이 특정 인스턴스에 집중되면, 해당 인스턴스가 과부하된다. 세션 타임아웃과 주기적 재균형이 필요하다.
FastMCP는 MCP 서버 구현을 극적으로 단순화한다. 데코레이터로 함수를 도구/리소스/프롬프트로 노출하고, Python 타입힌트에서 JSON Schema를 자동으로 생성한다.
# mig_monitor_server.py — MIG 모니터링 도구 서버import sysfrom fastmcp import FastMCP
mcp = FastMCP("mig-monitor", description="MIG 슬라이스 상태 모니터링")
@mcp.tool()def get_mig_status() -> dict: """현재 할당된 MIG 슬라이스의 GPU/메모리 사용률을 반환한다.""" import pynvml try: pynvml.nvmlInit() handle = pynvml.nvmlDeviceGetHandleByIndex(0) memory = pynvml.nvmlDeviceGetMemoryInfo(handle) util = pynvml.nvmlDeviceGetUtilizationRates(handle) pynvml.nvmlShutdown() return { "memory_used_mb": memory.used // (1024 * 1024), "memory_total_mb": memory.total // (1024 * 1024), "gpu_utilization_pct": util.gpu, } except Exception as e: # stderr로 로그 — stdout 오염 방지 print(f"[ERROR] {e}", file=sys.stderr) return {"error": str(e)}
@mcp.tool()def check_memory_pressure(threshold_pct: float = 80.0) -> dict: """메모리 사용률이 임계값을 초과하는지 확인한다.
Args: threshold_pct: 경고 임계값 (기본 80%). 0~100 범위. """ # 입력 검증 if not (0.0 <= threshold_pct <= 100.0): return {"error": "threshold_pct는 0~100 범위여야 합니다"} status = get_mig_status() if "error" in status: return status used_pct = (status["memory_used_mb"] / status["memory_total_mb"]) * 100 return { "used_pct": round(used_pct, 1), "threshold_pct": threshold_pct, "alert": used_pct > threshold_pct, }# mig_resource_server.py — MIG 상태 리소스 노출from fastmcp import FastMCP
mcp = FastMCP("mig-resources")
@mcp.resource("mig://gpu/{gpu_index}/status")def gpu_status(gpu_index: int) -> str: """특정 GPU의 MIG 상태를 텍스트로 반환한다.""" # 입력 검증: GPU 인덱스 범위 확인 if not (0 <= gpu_index < 8): return f"Error: gpu_index는 0~7 범위여야 합니다 (입력값: {gpu_index})" import pynvml pynvml.nvmlInit() handle = pynvml.nvmlDeviceGetHandleByIndex(gpu_index) name = pynvml.nvmlDeviceGetName(handle) memory = pynvml.nvmlDeviceGetMemoryInfo(handle) pynvml.nvmlShutdown() return ( f"GPU {gpu_index}: {name}\n" f"Memory: {memory.used // (1024*1024)}MB / " f"{memory.total // (1024*1024)}MB" )
@mcp.resource("mig://config/profiles")def mig_profiles() -> str: """사용 가능한 MIG 프로파일 목록을 반환한다.""" return ( "1g.10gb — 16 SM, 10GB HBM3 (max 7)\n" "2g.20gb — 32 SM, 20GB HBM3 (max 3)\n" "3g.40gb — 48 SM, 40GB HBM3 (max 2)\n" "7g.80gb — 132 SM, 80GB HBM3 (max 1)" )# mig_prompt_server.py — MIG 분석 프롬프트 템플릿from fastmcp import FastMCP
mcp = FastMCP("mig-prompts")
@mcp.prompt()def analyze_mig_allocation(student_count: int = 30) -> str: """수강생 수에 맞는 최적 MIG 분할 전략을 분석하는 프롬프트.""" return ( f"DGX H100 (8 GPU × 80GB HBM3)에서 {student_count}명의 " f"학생에게 MIG 슬라이스를 할당하려 합니다.\n\n" f"다음을 분석해 주세요:\n" f"1. 최적 프로파일 조합 (1g.10gb vs 혼합)\n" f"2. 여유 자원 활용 방안\n" f"3. 피크 시간대 리소스 경쟁 완화 전략" )
@mcp.prompt()def security_review_checklist() -> str: """MCP 서버 보안 검토 체크리스트 프롬프트.""" return ( "다음 MCP 서버 보안 항목을 검토해 주세요:\n" "1. 서버 패키지 출처 및 해시 검증\n" "2. 환경 변수 노출 범위\n" "3. 도구 설명(description)의 프롬프트 인젝션 패턴\n" "4. 외부 네트워크 호출 여부\n" "5. 파일시스템 접근 범위\n" "6. 입력 검증 및 에러 반환의 안전성" )MCP Inspector는 서버를 테스트하고 디버깅하는 공식 도구다:
# MCP Inspector 실행 (서버를 직접 지정)npx @modelcontextprotocol/inspector python mig_monitor_server.py
# 브라우저에서 http://localhost:6274 접속# → tools/list, tools/call, resources/list 등을 UI로 테스트Claude Desktop이나 Claude Code에서 MCP 서버를 연결하는 설정:
{ "mcpServers": { "mig-monitor": { "command": "python", "args": ["mig_monitor_server.py"], "env": { "CUDA_VISIBLE_DEVICES": "MIG-GPU-xxxx/0/0" } }, "filesystem": { "command": "npx", "args": ["-y", "@modelcontextprotocol/server-filesystem", "/workspace"] }, "git": { "command": "uvx", "args": ["mcp-server-git", "--repository", "."] } }}1g.10gb (10GB VRAM)로 LLM 추론이 가능한가? 4-bit 양자화 시 어느 규모의 모델까지 올릴 수 있는지 계산하라. (힌트: 7B 모델의 4-bit 양자화 ≈ 4GB)delete_file 도구에 접근해야 하는가?)DGX SSH 접속 및 MIG 확인
# SSH 접속ssh [학번]@dgx.chu.ac.kr
# MIG 프로파일 확인nvidia-smi mig -lgip
# 할당된 MIG 인스턴스 확인nvidia-smi mig -lgi
# 디바이스 UUID 확인nvidia-smi -L
# 결과를 캡처 (과제 제출용)nvidia-smi mig -lgi > ~/mig-status.txt프로젝트 구조 및 환경 설정
mkdir -p lab-03-mcp && cd lab-03-mcppython -m venv .venvsource .venv/bin/activate
# uv 사용 시 (권장)uv add "mcp[cli]" fastmcp pynvml
# pip 사용 시pip install fastmcp pynvmllab-03-mcp/├── mig_monitor_server.py # MCP 서버 (Tool + Resource + Prompt)├── mcp_config.json # MCP 설정├── governance.py # TBAC 기반 거버넌스 연동└── tests/ └── test_server.pyMIG 모니터링 MCP 서버 구현
import sysfrom fastmcp import FastMCP
mcp = FastMCP( "mig-monitor", description="MIG 슬라이스 상태 모니터링 및 관리")
@mcp.tool()def get_mig_status() -> dict: """현재 MIG 슬라이스의 GPU/메모리 사용률을 반환한다.""" try: import pynvml pynvml.nvmlInit() handle = pynvml.nvmlDeviceGetHandleByIndex(0) memory = pynvml.nvmlDeviceGetMemoryInfo(handle) util = pynvml.nvmlDeviceGetUtilizationRates(handle) pynvml.nvmlShutdown() return { "memory_used_mb": memory.used // (1024 * 1024), "memory_total_mb": memory.total // (1024 * 1024), "gpu_utilization_pct": util.gpu, "status": "ok", } except Exception as e: print(f"[ERROR] {e}", file=sys.stderr) return {"status": "error", "message": str(e)}
@mcp.tool()def check_memory_pressure(threshold_pct: float = 80.0) -> dict: """메모리 사용률이 임계값을 초과하는지 확인한다.""" if not (0.0 <= threshold_pct <= 100.0): return {"status": "error", "message": "threshold_pct는 0~100 범위여야 합니다"} status = get_mig_status() if status["status"] == "error": return status used_pct = (status["memory_used_mb"] / status["memory_total_mb"]) * 100 return { "used_pct": round(used_pct, 1), "threshold_pct": threshold_pct, "alert": used_pct > threshold_pct, }
@mcp.resource("mig://gpu/0/status")def gpu_status_resource() -> str: """GPU 0의 현재 상태를 텍스트로 반환한다.""" status = get_mig_status() if status["status"] == "error": return f"Error: {status['message']}" return ( f"Memory: {status['memory_used_mb']}MB / " f"{status['memory_total_mb']}MB\n" f"GPU Utilization: {status['gpu_utilization_pct']}%" )
@mcp.prompt()def gpu_analysis_prompt() -> str: """GPU 상태를 분석하는 구조화된 프롬프트 템플릿.""" return ( "현재 MIG 슬라이스의 GPU 상태를 분석해 주세요.\n\n" "분석 항목:\n" "1. 메모리 사용률이 임계값(80%)을 초과하는가?\n" "2. GPU 활용률이 비정상적으로 낮거나 높은가?\n" "3. 다른 학생의 워크로드에 영향을 줄 가능성이 있는가?\n" "4. 리소스 최적화를 위한 제안 사항" )
if __name__ == "__main__": mcp.run()MCP 설정 JSON 작성
{ "mcpServers": { "mig-monitor": { "command": "python", "args": ["mig_monitor_server.py"], "env": { "CUDA_VISIBLE_DEVICES": "MIG-GPU-xxxx/0/0" } } }}
MIG-GPU-xxxx/0/0은 Step 1에서 확인한 실제 UUID로 교체한다.
MCP Inspector로 검증
# Inspector 실행npx @modelcontextprotocol/inspector python mig_monitor_server.py
# 브라우저에서 http://localhost:6274 접속 후:# 1. tools/list → get_mig_status, check_memory_pressure 확인# 2. tools/call → get_mig_status 실행, JSON 응답 확인# 3. resources/list → mig://gpu/0/status 확인# 4. prompts/list → gpu_analysis_prompt 확인# 5. 스크린샷 캡처 (과제 제출용)TBAC 기반 거버넌스 연동 (작업 단위 도구 접근 제어)
# governance.py — 작업(Task) 단위로 MCP 도구 접근을 제어from enum import Enum
class Role(str, Enum): STUDENT = "student" TA = "ta" ADMIN = "admin"
# TBAC: 작업(Task) × 역할(Role) → 허용 도구(Tools)TBAC_POLICIES = { "monitoring": { # 모니터링 작업: 모든 역할이 조회 도구 사용 가능 Role.STUDENT: ["get_mig_status", "check_memory_pressure"], Role.TA: ["get_mig_status", "check_memory_pressure", "list_all_instances"], Role.ADMIN: ["*"], }, "administration": { # 관리 작업: 학생은 접근 불가 Role.STUDENT: [], Role.TA: ["list_all_instances", "get_instance_detail"], Role.ADMIN: ["*"], }, "code_review": { # 코드 리뷰 작업: 파일 읽기만 허용, 삭제/수정 불가 Role.STUDENT: ["read_file", "get_mig_status"], Role.TA: ["read_file", "get_mig_status", "run_linter"], Role.ADMIN: ["*"], },}
def authorize_tool_call(role: Role, task: str, tool_name: str) -> bool: """TBAC: 역할 + 작업 컨텍스트로 도구 접근 제어""" task_policy = TBAC_POLICIES.get(task, {}) allowed = task_policy.get(role, []) if "*" in allowed: return True return tool_name in allowed
# 사용 예시if __name__ == "__main__": # 학생이 모니터링 작업 중 상태 조회 → 허용 print(authorize_tool_call(Role.STUDENT, "monitoring", "get_mig_status")) # True # 학생이 관리 작업 중 인스턴스 삭제 → 거부 print(authorize_tool_call(Role.STUDENT, "administration", "delete_mig_instance")) # False # 학생이 코드 리뷰 중 파일 삭제 → 거부 print(authorize_tool_call(Role.STUDENT, "code_review", "delete_file")) # False # 관리자는 모든 작업의 모든 도구 허용 print(authorize_tool_call(Role.ADMIN, "administration", "delete_mig_instance")) # Truenvidia-smi mig -lgi로 할당된 MIG 인스턴스를 확인했는가?tools/list가 2개 이상의 도구를 반환하는가?get_mig_status 호출이 정상 JSON을 반환하는가?mig://gpu/0/status 리소스가 현재 메모리 사용량을 보여주는가?prompts/list에서 gpu_analysis_prompt가 확인되는가? (3대 프리미티브 완성)threshold_pct에 범위 밖 값(예: -10, 200)을 넣으면 안전한 에러를 반환하는가?student가 administration 작업의 도구를 호출하면 거부되는가?제출 마감: 2026-03-24 23:59
제출 경로: assignments/week-03/[학번]/
필수 요구사항:
1g.10gb × 7과 3g.40gb × 2 + 1g.10gb × 1 구성의 장단점을 SM 수, 메모리, 최대 인스턴스 관점에서 비교nodeAffinity를 사용하여 특정 MIG 프로파일이 있는 노드에만 Pod을 스케줄링하는 YAML 작성tools/list JSON-RPC 응답을 캡처한 스크린샷 또는 JSON 덤프 제출가산점 요소:
mig://gpu/{id}/metrics)1g.10gb 슬라이스에서 Llama-3-8B 4-bit 양자화 모델을 로드하여 추론 벤치마크 측정mcp.* + jwt.* 네임스페이스를 활용한 동적 정책 예시 포함